Start with Transformers for Beginners
copying to my new blog page from :https://medium.com/@bibhabasumohapatrabm/start-with-transformers-for-beginners-2-5040c2acab7b
Link to the previous blog — https://medium.com/@bibhabasumohapatrabm/start-with-transformers-for-beginners-54e147ca5a7c
Attention Mechanism fails as the RNN computations are inherently sequential and not parallel. In contrast, that is not the case with Transformers, So a new concept is introduced, instead of relying on the recurrence, we use special attention called self-attention.
“Attention in RNNs refers to the computing relevance of each encoder’s hidden state to the decoder’s hidden state. In RNNs we use the fixed embedding for each token.
Where “self” refers to the fact that these weights are computed for all hidden states, we use the sequence to compute the weighted average of each embedding.” — NLP with Transformers.
Summarizing in simple words:
So basically, in ATTENTION it’s like, we have to encode a vector of fixed length and wait for the corresponding output vector and repeat the process and at the same time input the outputs of the corresponding inputs and give that to the other time-stamped inputs to use attention.
Where “ SELF “ ATTENTION helps us to get outputs and attention simultaneously, weights are different for each input embedding -
\[\bar{x}_i = \sum w_{ij} x_i\]
Q → What are contextualized embeddings?
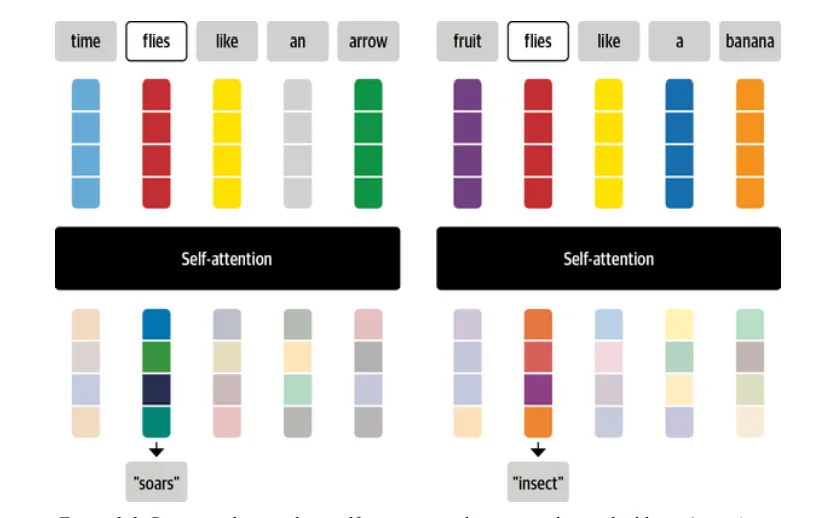
Example: ”Time flies like an arrow” → flies here is referred to as a verb.
rather than insects.
contextual embeddings:
We use the representation of the word, that fits the context i.e. the words neighboring the word “flies”, “Time” and “Arrow” tells us that “flies” is Verb. Hence, providing more weight Wij to the embeddings of “Time” and “Arrow” will be a better choice, and embeddings generated this way are called Contextualized Embeddings.
In the Paper “Attention is all you need”
We were introduced to the Scaled- dot product Attention:
Scaled-dot Attention is one of the ways to implement self-attention layers -
we have three vectors query, key, and value. a good example in the Book NLP with transformers makes it easy to understand what is a query, key, and value. When we go to the Supermarket, we have a dish recipe and the ingredients in the recipe are queries. — As you scan through shelves, you will check every label. So labels are key. — When you have while scanning, you take that item. So the item is the value. 2. We calculate how much query and key relate/are similar to each other, we do this by dot product, for more about similarity and dot-product → go to this blog by me. we gt Q.K (dot product) → these dot products are called attention scores, So if there are N inputs then there is an NxN matrix of Attention scores
- To normalize large values, attention scores are multiplied by a scaling factor to normalize and then normalized with a softmax to ensure all the column values sum to 1. We get, attention weights Wij
\[w_{ij} = \text{Normalized}(Q \cdot K)\]
- Once we get Attention to weights,
we multiply them by value vector (v_1, v_2, , v_N). So we have an updated embedding \[ \bar{x}_i = \sum w_{ij} x_j \]
How to implement what we learned? How to do it from scratch? this is in the 3rd chapter of Natural Language Processing with Transformers with Hugging Face.
I will cover it in the next blog . . . stay with me!!!!
RESOURCES : (treat it as notes from CS224n and mentioned book )
→ Stanford Youtube CS224n and slides
→ Natural Language Processing with Transformers with Hugging Face Chapter 3